Multi-tenant Orchestration Platform for Distributed Job Execution in Cloud and On-premises Environments
Vertex Systems have always offered Master´s Thesis opportunities to university students to support their academic and professional qualifications. There are more than 40 Master´s Theses completed for Vertex during the years. The research results are implemented in our product development to provide cutting-edge software solutions for our customers.
In the “My Master´s Thesis Journey” blog series, our young professionals tell about their Master´s theses and what they have learned and accomplished during the journey.”
Huhtikuu 2026
Eemeli Mark
Ohjelmistosuunnittelija

Background
I joined Vertex Systems in spring 2022. After that, I completed my military service, and later returned to continue working at Vertex alongside my university studies. Over time, this path led naturally to my master’s thesis, which was completed as part of my studies in Information Technology at the University of Jyväskylä and carried out for Vertex Systems Oy.
The thesis focused on designing, implementing, and evaluating a multi-tenant orchestration platform for distributed job execution that supports both cloud and on-premises environments. The topic emerged from a practical software engineering need common in modern systems. Applications often need to perform computationally intensive or long-running work in the background. When that work is executed directly inside user-facing services, it can reduce responsiveness and limit scalability. In practice, this leads to a slower user experience and tighter coupling between interactive workflows and heavy processing.
The goal of the thesis was to build a platform that offloads heavy background work in a structured and reliable way. At the same time, the solution needed to support constraints that are important in real deployments, including multi-tenancy, multiple job types and priorities, operation in both cloud and onpremises environments, and secure access control with centralized identity management.
Building the platform
The implemented platform is built around a centralized orchestrator service and a set of distributed workers. In short, the orchestrator receives job submissions, stores job metadata in PostgreSQL, queues jobs through RabbitMQ, and dispatches them to suitable workers via SignalR. Workers execute the jobs and report progress and final results back to the orchestrator.
The high-level architecture is shown below. It illustrates how the client interacts with Keycloak for authentication, submits jobs to the orchestrator, and how the orchestrator coordinates state persistence, caching, and distributed execution through the infrastructure components.
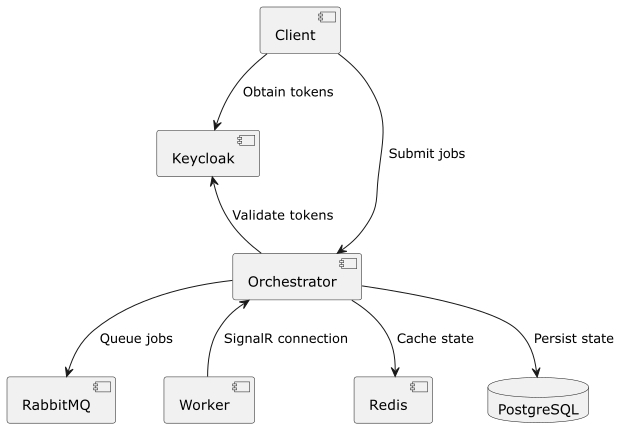
A key design goal was to separate responsibilities clearly:
- RabbitMQ provides durable queuing and buffering for jobs
- SignalR provides a real-time coordination channel between orchestrator and workers
- PostgreSQL stores persistent job and worker metadata
- Redis is used for SignalR backplane support and idempotency handling
- Keycloak provides centralized authentication and authorization for users and services
This combination made it possible to build a platform that is reliable and modular while still staying practical to operate. The architecture also supports strong tenant isolation by scoping job submission, dispatch, and status access to the correct tenant, while still allowing controlled fallback behavior through globally configured workers when needed. One implementation choice that was especially interesting was using SignalR as the coordination channel for distributed job execution. In this platform, it fit well with the push-based dispatch model and the chosen technology stack.
To illustrate how the platform behaves during execution, the sequence below shows the main job lifecycle from submission to completion or failure. It highlights how the orchestrator creates the job record, enqueues the job, leases the job to a worker, and updates the final status based on the execution outcome.
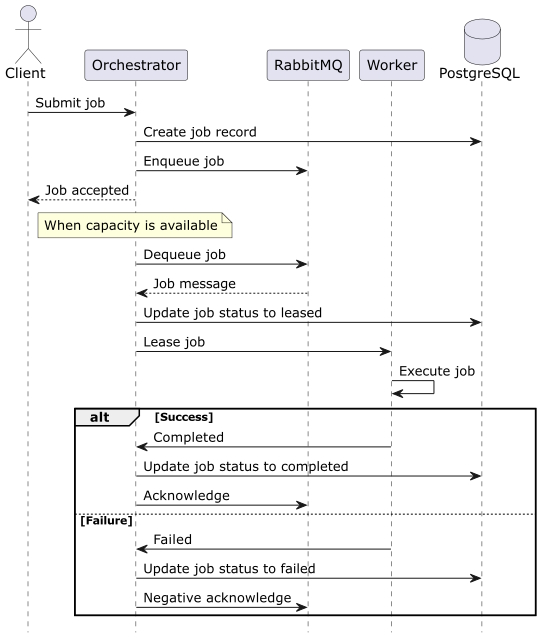
This flow also demonstrates an important reliability principle in the implementation. Job state transitions are tracked explicitly, and worker failures do not block the system from continuing to process other jobs. Failed jobs can be negatively acknowledged and requeued according to the configured handling logic.
Evaluation and results
The platform was evaluated using test scenarios focused on general platform behavior rather than any single specific job type. The evaluation covered latency, throughput, fault tolerance, duplicate delivery handling, priority dispatch, tenant isolation, and resource usage.
The results were encouraging:
- Under light load, baseline jobs reached the completed state within 100 ms for at least 95% of observations
- Throughput increased as more workers were added, and the tested range did not show control plane becoming the bottleneck
- Failure recovery behaved as expected, when a worker failed during execution, the affected job was requeued automatically while other jobs continued
- Duplicate submission handling worked correctly through idempotency keys
- Priority dispatch and tenant isolation behaved as intended
- Control plane resource usage remained low during the evaluation
In other words, the evaluation showed that the platform meets the key goals for reliable background job offloading under the tested conditions, while leaving room for future scaling by increasing worker capacity and, if needed, scaling the orchestrator horizontally.
Conclusions
This thesis gave me the opportunity to work on a real distributed systems problem from end to end, from requirements to implementation, testing, and evaluation. Beyond the technical implementation itself, the project helped me better understand what it takes to turn an architectural idea into something that can be built, tested, maintained, and evolved in practice.
The main outcome of the thesis is a concrete platform design and implementation that improves how heavy background jobs can be handled without coupling them tightly to user-facing services. The platform supports scalable and reliable processing, better operational visibility, and a structured path for integrating background execution into existing systems.
For me personally, this was a motivating and rewarding project. It deepened my understanding of distributed systems and provided a strong foundation for future development work around background processing and orchestration.